Taming Big Data with MapReduce and Hadoop Hands On (Udemy.com)
Learn MapReduce fast by building over 10 real examples, using Python, MRJob, and Amazon's Elastic MapReduce Service.
Created by: Frank Kane
Produced in 2022
 What you will learn
What you will learn
- Understand how MapReduce can be used to analyze big data sets
- Write your own MapReduce jobs using Python and MRJob
- Run MapReduce jobs on Hadoop clusters using Amazon Elastic MapReduce
- Chain MapReduce jobs together to analyze more complex problems
- Analyze social network data using MapReduce
- Analyze movie ratings data using MapReduce and produce movie recommendations with it.
- Understand other Hadoop-based technologies, including Hive, Pig, and Spark
- Understand what Hadoop is for, and how it works
 Quality Score
Quality Score
Overall Score : 0 / 100
 Live Chat with CourseDuck's Co-Founder for Help
Live Chat with CourseDuck's Co-Founder for Help
 Course Description
Course Description
Learn and master the art of framing data analysis problems as MapReduce problems through over 10 hands-on examples, and then scale them up to run on cloud computing services in this course. You'll be learning from an ex-engineer and senior manager from Amazon and IMDb.
Learn the concepts of MapReduce
Run MapReduce jobs quickly using Python and MRJob
Translate complex analysis problems into multi-stage MapReduce jobs
Scale up to larger data sets using Amazon's Elastic MapReduce service
Understand how Hadoop distributes MapReduce across computing clusters
Learn about other Hadoop technologies, like Hive, Pig, and Spark
By the end of this course, you'll be running code that analyzes gigabytes worth of information in the cloud in a matter of minutes.
We'll have some fun along the way. You'll get warmed up with some simple examples of using MapReduce to analyze movie ratings data and text in a book. Once you've got the basics under your belt, we'll move to some more complex and interesting tasks. We'll use a million movie ratings to find movies that are similar to each other, and you might even discover some new movies you might like in the process! We'll analyze a social graph of superheroes, and learn who the most popular" superhero is and develop a system to find degrees of separation" between superheroes. Are all Marvel superheroes within a few degrees of being connected to The Incredible Hulk? You'll find the answer.
This course is very hands-on; you'll spend most of your time following along with the instructor as we write, analyze, and run real code together both on your own system, and in the cloud using Amazon's Elastic MapReduce service. Over 5 hours of video content is included, with over 10 real examples of increasing complexity you can build, run and study yourself. Move through them at your own pace, on your own schedule. The course wraps up with an overview of other Hadoop-based technologies, including Hive, Pig, and the very hot Spark framework complete with a working example in Spark.
Don't take my word for it - check out some of our unsolicited reviews from real students:
"I have gone through many courses on map reduce; this is undoubtedly the best, way at the top."
"This is one of the best courses I have ever seen since 4 years passed I am using Udemy for courses."
"The best hands on course on MapReduce and Python. I really like the run it yourself approach in this course. Everything is well organized, and the lecturer is top notch."
Who this course is for:
This course is best for students with some prior programming or scripting ability. We will treat you as a beginner when it comes to MapReduce and getting everything set up for writing MapReduce jobs with Python, MRJob, and Amazon's Elastic MapReduce service - but we won't spend a lot of time teaching you how to write code. The focus is on framing data analysis problems as MapReduce problems and running them either locally or on a Hadoop cluster. If you don't know Python, you'll need to be able to pick it up based on the examples we give. If you're new to programming, you'll want to learn a programming or scripting language before taking this course.

*Some courses are excluded from this sale. Coupon not working? If the link above doesn't drop prices, clear the cookies in your browser and then click this link here.
Also, you may need to apply the coupon code directly on the cart page to get the discount.
 Instructor Details
Instructor Details

- 0.0 Rating
 0 Reviews
0 Reviews
Frank Kane
Frank spent 9 years at Amazon and IMDb, developing and managing the technology that automatically delivers product and movie recommendations to hundreds of millions of customers, all the time. Frank holds 17 issued patents in the fields of distributed computing, data mining, and machine learning. In 2012, Frank left to start his own successful company, Sundog Software, which focuses on virtual reality environment technology, and teaching others about big data analysis.
 Reviews
Reviews

- Video Duration:
 5h
5h - Price: 11.99 Track Price 11.99 Track Price
- Provider:
 Udemy
Udemy - Year:
 2022
2022 - Level:
 Beginner
Beginner - Language:
 English
English - Certificate:
 Yes
Yes

30-Day Money-Back Guarantee
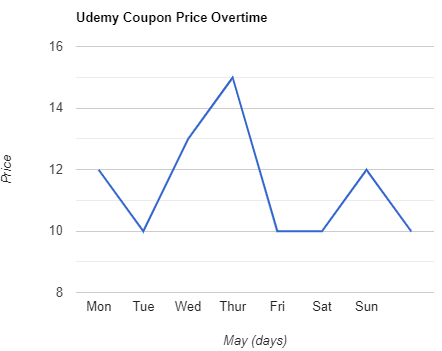
Udemy Coupon Price Tracker