The Ultimate Hands On Hadoop Tame your Big Data (Udemy.com)
Hadoop tutorial with MapReduce, HDFS, Spark, Flink, Hive, HBase, MongoDB, Cassandra, Kafka + more! Over 25 technologies.
Created by: Frank Kane
Produced in 2022
 What you will learn
What you will learn
- Design distributed systems that manage "big data" using Hadoop and related technologies.
- Use HDFS and MapReduce for storing and analyzing data at scale.
- Use Pig and Spark to create scripts to process data on a Hadoop cluster in more complex ways.
- Analyze relational data using Hive and MySQL
- Analyze non-relational data using HBase, Cassandra, and MongoDB
- Query data interactively with Drill, Phoenix, and Presto
- Choose an appropriate data storage technology for your application Understand how Hadoop clusters are managed by YARN, Tez, Mesos, Zookeeper, Zeppelin, Hue, and Oozie.
- Publish data to your Hadoop cluster using Kafka, Sqoop, and Flume
- Consume streaming data using Spark Streaming, Flink, and Storm
 Quality Score
Quality Score
Overall Score : 0 / 100
 Live Chat with CourseDuck's Co-Founder for Help
Live Chat with CourseDuck's Co-Founder for Help
 Course Description
Course Description
Learn and master the most popular big data technologies in this comprehensive course, taught by a former engineer and senior manager from Amazon and IMDb. We'll go way beyond Hadoop itself, and dive into all sorts of distributed systems you may need to integrate with.
Install and work with a real Hadoop installation right on your desktop with Hortonworks (now part of Cloudera) and the Ambari UI
Manage big data on a cluster with HDFS and MapReduce
Write programs to analyze data on Hadoop with Pig and Spark
Store and query your data with Sqoop, Hive, MySQL, HBase, Cassandra, MongoDB, Drill, Phoenix, and Presto
Design real-world systems using the Hadoop ecosystem
Learn how your cluster is managed with YARN, Mesos, Zookeeper, Oozie, Zeppelin, and Hue
Handle streaming data in real time with Kafka, Flume, Spark Streaming, Flink, and Storm
Understanding Hadoop is a highly valuable skill for anyone working at companies with large amounts of data.
Almost every large company you might want to work at uses Hadoop in some way, including Amazon, Ebay, Facebook, Google, LinkedIn, IBM, Spotify, Twitter, and Yahoo! And it's not just technology companies that need Hadoop; even the New York Times uses Hadoop for processing images.
This course is comprehensive, covering over 25 different technologies in over 14 hours of video lectures. It's filled with hands-on activities and exercises, so you get some real experience in using Hadoop - it's not just theory.
You'll find a range of activities in this course for people at every level. If you're a project manager who just wants to learn the buzzwords, there are web UI's for many of the activities in the course that require no programming knowledge. If you're comfortable with command lines, we'll show you how to work with them too. And if you're a programmer, I'll challenge you with writing real scripts on a Hadoop system using Scala, Pig Latin, and Python.
You'll walk away from this course with a real, deep understanding of Hadoop and its associated distributed systems, and you can apply Hadoop to real-world problems. Plus a valuable completion certificate is waiting for you at the end!
Please note the focus on this course is on application development, not Hadoop administration. Although you will pick up some administration skills along the way.
Knowing how to wrangle "big data" is an incredibly valuable skill for today's top tech employers. Don't be left behind - enroll now!
"The Ultimate Hands-On Hadoop... was a crucial discovery for me. I supplemented your course with a bunch of literature and conferences until I managed to land an interview. I can proudly say that I landed a job as a Big Data Engineer around a year after I started your course. Thanks so much for all the great content you have generated and the crystal clear explanations. " - Aldo Serrano
"I honestly wouldnt be where I am now without this course. Frank makes the complex simple by helping you through the process every step of the way. Highly recommended and worth your time especially the Spark environment. This course helped me achieve a far greater understanding of the environment and its capabilities. Frank makes the complex simple by helping you through the process every step of the way. Highly recommended and worth your time especially the Spark environment." - Tyler Buck
Who this course is for:
Software engineers and programmers who want to understand the larger Hadoop ecosystem, and use it to store, analyze, and vend "big data" at scale.
Project, program, or product managers who want to understand the lingo and high-level architecture of Hadoop.
Data analysts and database administrators who are curious about Hadoop and how it relates to their work.
System architects who need to understand the components available in the Hadoop ecosystem, and how they fit together.

*Some courses are excluded from this sale. Coupon not working? If the link above doesn't drop prices, clear the cookies in your browser and then click this link here.
Also, you may need to apply the coupon code directly on the cart page to get the discount.
 Instructor Details
Instructor Details

- 0.0 Rating
 0 Reviews
0 Reviews
Frank Kane
Frank spent 9 years at Amazon and IMDb, developing and managing the technology that automatically delivers product and movie recommendations to hundreds of millions of customers, all the time. Frank holds 17 issued patents in the fields of distributed computing, data mining, and machine learning. In 2012, Frank left to start his own successful company, Sundog Software, which focuses on virtual reality environment technology, and teaching others about big data analysis.
 Reviews
Reviews

- Video Duration:
 14.5h
14.5h - Price: 11.99 Track Price 11.99 Track Price
- Provider:
 Udemy
Udemy - Year:
 2022
2022 - Level:
 Beginner
Beginner - Language:
 English
English - Certificate:
 Yes
Yes

30-Day Money-Back Guarantee
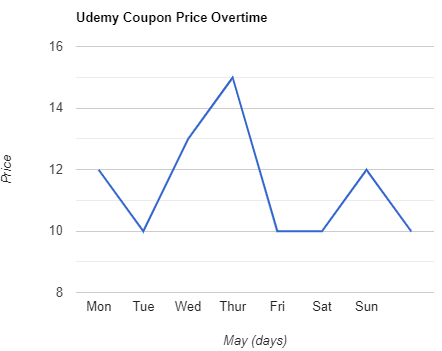
Udemy Coupon Price Tracker